


About MCaaS
Advanced Deployment Strategies
Overview
Advanced deployment/Progressive delivery is the next step after continuous delivery, where new versions are deployed to a subset of users and are evaluated in terms of percision and performance before rolling them to the totality of the users and rolled back if not matching some key metrics. To achieve this, MCaaS has implemented Flagger in to our environment. Flagger is an automating tool for progressive deliveries and helps with safer releases
What is Flagger?
Flagger automates the process of creating new Kubernetes resources, watching metrics and reduces the risk of introducing a new software version in production by gradually shifting traffic to the new version while measuring metrics like HTTP request success rate and latency.
How does Flagger work?
Flagger uses a service mesh, istio, that runs in a cluster to manage the traffic that goes between one deployment and another. Let’s assume you’re running a micro-service with 1.0 version and you decide to upgrade that service to 1.1 version. Once you check in the updated code into Git, Flagger will take your existing 1.0 service pod and create a new pod with primary prefix in the name and then setup a second deployment of the service, which is called Canary. That Canary will hold the latest version, 1.1.
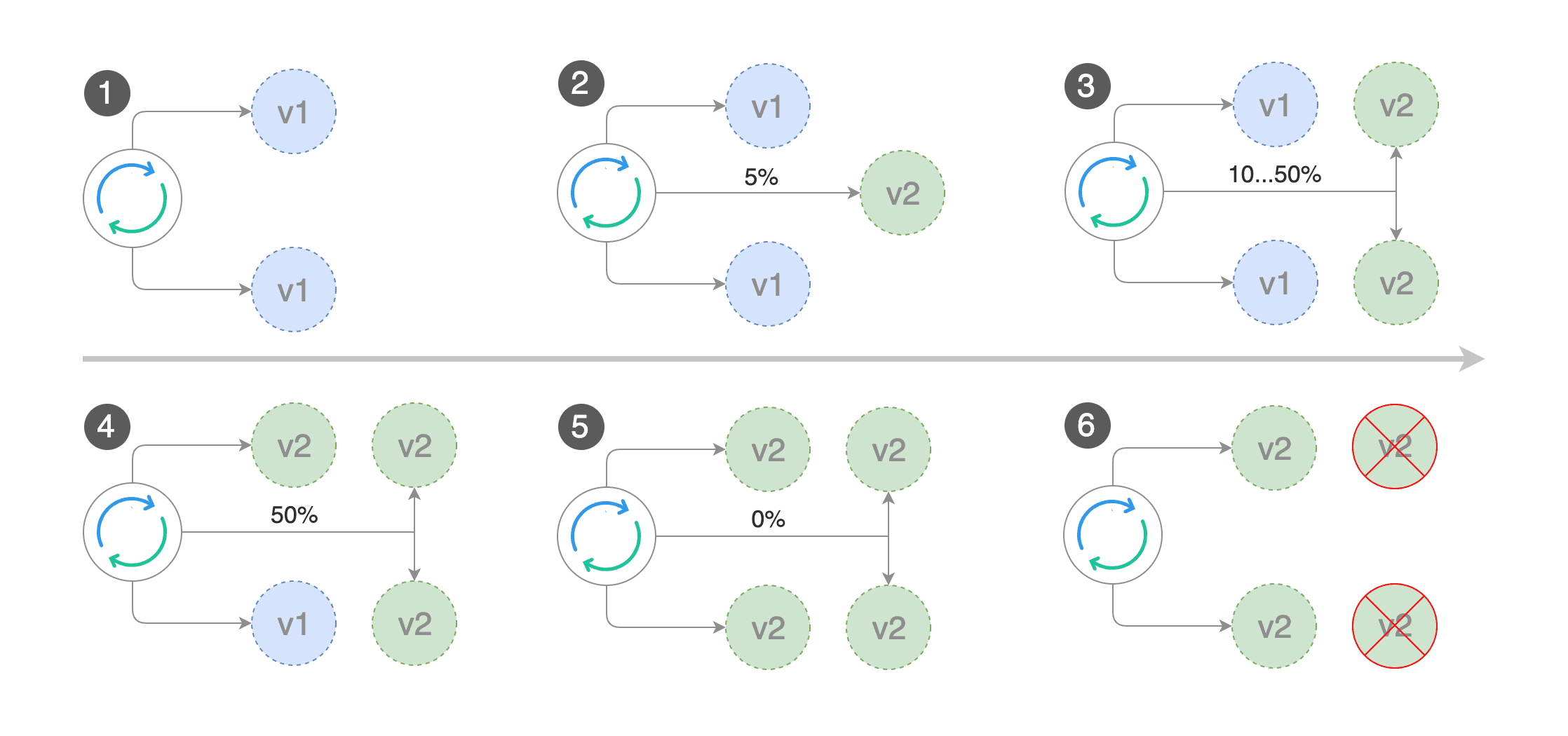
As mentioned above, Flagger sets up the two versions of the service and it uses the service mesh,istio, to direct traffic from the main service to the new service in small increments, say 5% at a time. Then it will increase those increments for a period of time until it reaches a threshold that you define, say 50% of all the traffic. Once it reaches that threshold without experiencing a lot of errors, and you can also set the threshold at how many errors it would experience before it gives up and rolls back, if it reaches that threshold successfully then it will cut over all of the traffic to the new service (1.1) and then that service becomes the primary and the old ones becomes your canary.
Types of Strategies
Flagger can run automated application analysis, testing, promotion and rollback for the following deployment strategies:
- Canary (progressive traffic shifting)
- A/B Testing (HTTP headers and cookies traffic routing)
- Blue/Green (traffic switching and mirroring)
Canary Release
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs, a canary is promoted or aborted.
Istio example:
analysis:
# schedule interval (default 60s)
interval: 15s
# max number of failed metric checks before rollback
threshold: 5
# max traffic percentage routed to canary [percentage (0-100)]
maxWeight: 5
Canary promotion stages:
- scan for canary deployments
- check primary and canary deployment status
- halt advancement if a rolling update is underway
- halt advancement if pods are unhealthy
- call confirm-rollout webhooks and check results
- halt advancement if any hook returns a non HTTP 2xx result
- call pre-rollout webhooks and check results
- halt advancement if any hook returns a non HTTP 2xx result
- increment the failed checks counter
- increase canary traffic weight percentage from 0% to 2% (step weight)
- call rollout webhooks and check results
- check canary HTTP request success rate and latency
- halt advancement if any metric is under the specified threshold
- increment the failed checks counter
- check if the number of failed checks reached the threshold
- route all traffic to primary
- scale to zero the canary deployment and mark it as failed
- call post-rollout webhooks
- post the analysis result to Slack
- wait for the canary deployment to be updated and start over
- increase canary traffic weight by 2% (step weight) till it reaches 50% (max weight)
- halt advancement if any webhook call fails
- halt advancement while canary request success rate is under the threshold
- halt advancement while canary request duration P99 is over the threshold
- halt advancement while any custom metric check fails
- halt advancement if the primary or canary deployment becomes unhealthy
- halt advancement while canary deployment is being scaled up/down by HPA
- call confirm-promotion webhooks and check results
- halt advancement if any hook returns a non HTTP 2xx result
- promote canary to primary
- copy ConfigMaps and Secrets from canary to primary
- copy canary deployment spec template over primary
- wait for primary rolling update to finish
- halt advancement if pods are unhealthy
- route all traffic to primary
- scale to zero the canary deployment
- mark rollout as finished
- call post-rollout webhooks
- send notification with the canary analysis result (optional)
- wait for the canary deployment to be updated and start over
A/B Testing
For frontend applications that require session affinity you should use HTTP headers or cookies match conditions to ensure a set of users will stay on the same version for the whole duration of the canary analysis.
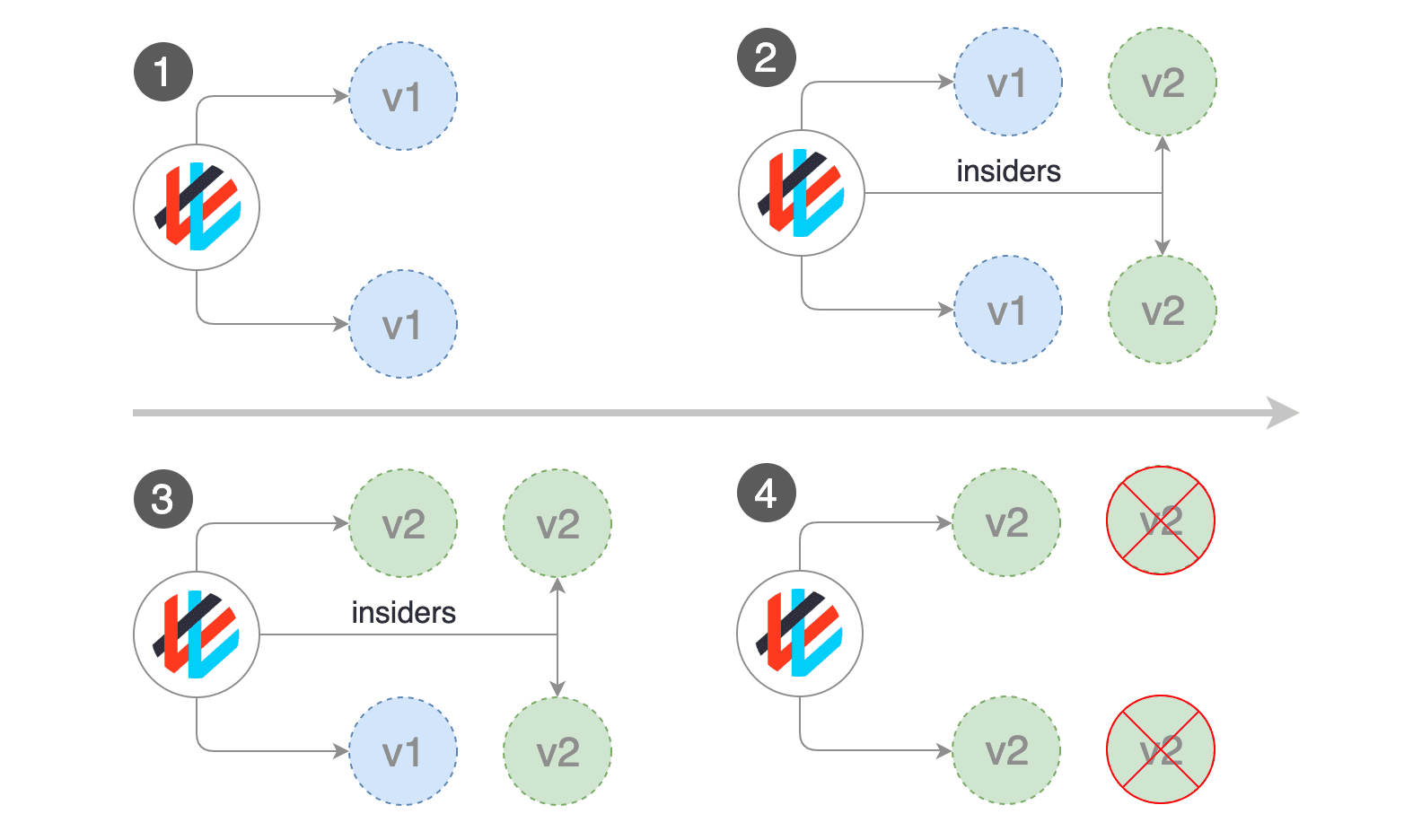
You can enable A/B testing by specifying the HTTP match conditions and the number of iterations. If Flagger finds a HTTP match condition, it will ignore the maxWeight and stepWeight settings.
Istio example:
analysis:
- schedule interval (default 60s)
interval: 1m
- total number of iterations
iterations: 10
- max number of failed iterations before rollback
threshold: 2
- canary match condition
match:
- headers:
x-canary:
regex: ".*insider.*"
- headers:
cookie:
regex: "^(.*?;)?(canary=always)(;.*)?$"
The above configuration will run an analysis for ten minutes targeting the Safari users and those that have a test cookie. You can determine the minimum time that it takes to validate and promote a canary deployment using this formula:
interval * iterations
And the time it takes for a canary to be rollback when the metrics or webhook checks are failing:
interval * threshold
Istio example:
analysis:
interval: 1m
threshold: 10
iterations: 2
match:
- headers:
x-canary:
exact: "insider"
- headers:
cookie:
regex: "^(.*?;)?(canary=always)(;.*)?$"
- sourceLabels:
app.kubernetes.io/name: "scheduler"
The header keys must be lowercase and use hyphen as the separator. Header values are case-sensitive and formatted as follows:
-
exact: "value"for exact string match -
prefix: "value"for prefix-based match -
suffix: "value"for suffix-based match -
regex: "value"for style regex-based match
Blue/Green Deployments with Traffic Mirroring
Traffic Mirroring is a pre-stage in a Canary (progressive traffic shifting) or Blue/Green deployment strategy. Traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service. The response from the primary is sent back to the user. The response from the canary is discarded. Metrics are collected on both requests so that the deployment will only proceed if the canary metrics are healthy.
Mirroring should be used for requests that are idempotent or capable of being processed twice (once by the primary and once by the canary). Reads are idempotent. Before using mirroring on requests that may be writes, you should consider what will happen if a write is duplicated and handled by the primary and canary.
To use mirroring, set spec.analysis.mirror to true.
Istio example:
analysis:
# schedule interval (default 60s)
interval: 1m
# total number of iterations
iterations: 10
# max number of failed iterations before rollback
threshold: 2
# Traffic shadowing (compatible with Istio only)
mirror: true
# Weight of the traffic mirrored to your canary (defaults to 100%)
mirrorWeight: 100
Mirroring rollout steps for service mesh:
- detect new revision (deployment spec, secrets or configmaps changes)
- scale from zero the canary deployment
- wait for the HPA to set the canary minimum replicas
- check canary pods health
- run the acceptance tests
- abort the canary release if tests fail
- start the load tests
- mirror 100% of the traffic from primary to canary
- check request success rate and request duration every minute
- abort the canary release if the failure threshold is reached
- stop traffic mirroring after the number of iterations is reached
- route live traffic to the canary pods
- promote the canary (update the primary secrets, configmaps and deployment spec)
- wait for the primary deployment rollout to finish
- wait for the HPA to set the primary minimum replicas
- check primary pods health
- switch live traffic back to primary
- scale to zero the canary
- send notification with the canary analysis result (optional)
After the analysis finishes, the traffic is routed to the canary (green) before triggering the primary (blue) rolling update, this ensures a smooth transition to the new version avoiding dropping in-flight requests during the Kubernetes deployment rollout.
Examples
canary:
enabled: true
hpa:
enabled: false
skipAnalysis: false
analysis:
# schedule interval (default 60s)
interval: 15s
# max number of failed metric checks before rollback
threshold: 5
# max traffic percentage routed to canary [percentage (0-100)]
maxWeight: 50
# canary increment step [percentage (0-100)]
stepWeight: 5
# checks
metrics:
- name: "404s percentage"
templateRef:
name: not-found-percentage
namespace: istio-system
thresholdRange:
max: 5
interval: 15s
In this example, MCaaS team is using canary release strategy for the demo application. For the Metrics, we’re using a basic custom metric where it checks for HTTP 404 response code.
apiVersion: flagger.app/v1beta1
kind: MetricTemplate
metadata:
name: not-found-percentage
namespace: istio-system
spec:
provider:
type: datadog
address: https://api.datadoghq.com
secretRef:
name: datadog
query: |
100 - sum:istio.mesh.request.count{
reporter:destination,
destination_service_namespace:{{ namespace }},
destination_service_name:{{ target }},
!response_code:404}.as_count()
/
sum:istio.mesh.request.count{
reporter:destination,
destination_service_namespace:{{ namespace }},
destination_service_name:{{ target }}}.as_count()*100
For additional information on Flagger, please visit Flagger’s official documentation portal.
- On this page: